기본 파일 시스템은 외부 단편화에 취약한 single extent로 파일을 할당한다. 즉 n-block 파일은 n개의 블록이 할당 가능 상태일지라도 할당되지 않는다(외부 단편화 얘기). on-disk inode 구조체를 수정하여 이 문제를 제거해라.
on-disk inode 구조체가 뭘까. 확인해봐야겠지? 이 구조체는 filesys/inode.c 에 있다.
/* On-disk inode.
* Must be exactly DISK_SECTOR_SIZE bytes long. */
struct inode_disk {
disk_sector_t start; /* First data sector. */
off_t length; /* File size in bytes. */
unsigned magic; /* Magic number. */
uint32_t unused[125]; /* Not used. */
};여기서 start 멤버는 시작 블록번호를 뜻하고,
length는 할당된 블록길이(byte)로 파일 생성 시, 디스크 상에 연속된 블록을 할당 받는다.

일단 깃북을 계속 읽어보자. 파일 시스템 할당을 더 쉽게 구현하기 위해서 FAT(file allocation table)을 구현하라고 한다.
Indexing large files with FAT
외부 단편화를 완화하기 위해 클러스터 크기를 축소할 수 있다. 단순화를 위해 기본 코드에서 클러스터의 섹터 수를 1로 고정한다. 하지만 이렇게 소규모 클러스터를 사용하면 클러스터가 전체 파일을 저장하기 부족할 수 있다. 이 경우 파일 하나에 여러 개의 클러스터가 필요하기 때문에 inode에 있는 파일의 클러스터를 인덱싱하기 위한 자료 구조가 필요하다. 가장 쉬운 방법 중 하나는 linked-list를 사용하는 것이다. inode는 파일의 첫 번째 블록의 섹터 번호를 포함할 수 있으며 첫 번째 블록은 두 번째 블록의 섹터 번호를 포함할 수 있다.

하지만 이런 방식은 파일의 모든 블록을 읽게 되어서 속도가 느리고 직접 접근에도 비효율적이다. 또한 포인터 저장을 위한 공간도 필요하기 때문에 공간 활용에 비효율적이다.
(무엇보다 포인터 잘못 건드려서 문제 스노우볼 굴러가는 것 상상만 해도 머리 아픔...)
이를 해결하기 위해 FAT를 사용한다(블록 자체보다는 고정된 사이즈의 FAT에 블록의 연결 배치). FAT에는 실제 데이터가 아닌 연결 값만 포함되기 때문에 크기가 작아 DRAM에 캐싱할 수 있다.
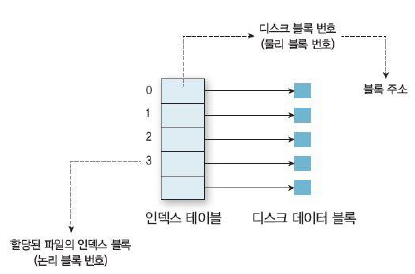
filesys/fat.c에 있는 스켈레톤 코드에 inode indexing을 구현해라.
filesys/fat.c 에 가면 fat_init(), fat_open(), fat_close(), fat_create(), fat_boot_create() 함수들이 있는데, 수정할 필요 없다. fat_fs_init()만 수정하면 된다.
void fat_fs_init (void) {
/* TODO: Your code goes here. */
}
이 함수는 FAT 파일 시스템을 초기화하는 함수다. fat_fs의 fat_length와 data_start 필드를 초기화해야 한다.
/* FAT FS */
struct fat_fs {
struct fat_boot bs;
unsigned int *fat;
unsigned int fat_length; // 파일 시스템에 많은 클러스터들 저장
disk_sector_t data_start; // 파일을 저장할 수 있는 섹터를 저장
cluster_t last_clst;
struct lock write_lock;
};
fat_fs_init() 구현
void fat_fs_init (void) {
/* TODO: Your code goes here. */
// FAT byte 크기
// FAT의 섹터 수 X 512bytes / cluster 당 sector 수
fat_fs->fat_length = fat_fs->bs.fat_sectors * DISK_SECTOR_SIZE / (sizeof(cluster_t) * SECTORS_PER_CLUSTER);
//! DATA sector가 시작하는 지점
fat_fs->data_start = fat_fs->bs.fat_start + fat_fs->bs.fat_sectors;
}
궁금한 점. 여기서 fat_fs 구조체에서 bs, fat_boot이 뭐지?
/* Should be less than DISK_SECTOR_SIZE */
struct fat_boot {
unsigned int magic;
unsigned int sectors_per_cluster; /* Fixed to 1 */
unsigned int total_sectors;
unsigned int fat_start;
unsigned int fat_sectors; /* Size of FAT in sectors. */
unsigned int root_dir_cluster;
};
일단 구조체를 봐서는 전체 파일 시스템의 정보를 담는 구조체라고 생각해야겠다.
다음은 cluster_t fat_fs_init() 함수를 구현하라고 한다.
이 함수는 clst(클러스터 인덱싱 번호)에 지정된 클러스터 뒤에 클로스터를 추가하여 체인을 확장한다. 만약 clst가 0이라면, 새로운 체인을 생성한다. 새로 할당된 클러스터의 클러스터 번호를 리턴하면 된다.
/* Add a cluster to the chain.
* If CLST is 0, start a new chain.
* Returns 0 if fails to allocate a new cluster. */
cluster_t fat_create_chain (cluster_t clst) {
/* TODO: Your code goes here. */
cluster_t i = 2;
while (fat_get(i) != 0 && i < fat_fs->fat_length) {
++i;
}
if (i == fat_fs->fat_length) { // FAT가 가득 찼다면
return 0;
}
fat_put(i, EOChain); // fat안의 값 업데이트
if (clst == 0) { // 새로운 체인 생성
return i;
}
while(fat_get(clst) != EOChain) {
clst = fat_get(clst);
}
fat_put(clst, i);
return i;
}
여기서 fat_get()은 클러스터 clst로 주어진 클러스터의 번호를 불러오는 함수고, fat_put()은 clst에 val 값으로 업데이트하는 함수다. 테이블의 각 엔트리들의 연결을 위해 필요한 함수임! 아래처럼 구현
/* Update a value in the FAT table. */
void fat_put (cluster_t clst, cluster_t val) {
/* TODO: Your code goes here. */
fat_fs->fat[clst] = val;
}
/* Fetch a value in the FAT table. */
cluster_t fat_get (cluster_t clst) {
/* TODO: Your code goes here. */
return fat_fs->fat[clst];
}
다음은 cluster_to_sector() 함수 구현이다. 이 함수는 클러스터 번호 clst를 해당 섹터 번호로 반환한다.
/* Convert a cluster # to a sector number. */
disk_sector_t cluster_to_sector (cluster_t clst) {
/* TODO: Your code goes here. */
return fat_fs->data_start + clst;
}
다음으로 extensible file을 구현해야 한다. 기본 파일 시스템에서 파일 사이즈는 파일이 생성될 때 명시된다. 그러나 대부분 현대 파일 시스템에서 파일은 초기에 사이즈 0으로 생성되고 파일 끝 부분에 쓰여질 때마다(write) 확장된다.
파일 시스템은 이런 사항들을 따라야 한다.
- 파일이 파일 시스템 크기(메타 데이터 제외)를 초과할 수 없다는 점을 제외하고는 파일의 크기에 미리 결정된 제한이 없어야 한다. 이는 또한 루트 디렉토리 파일에도 적용이 되며, 초기 제한인 16개 파일 이상으로 확장될 수 있다.
- 유저 프로그램은 현재의 end-of-file(EOF)를 넘어 탐색할 수 있다. 탐색 자체는 파일을 확장하지 않는다. EOF를 지난 위치에서 writing하는 것은 파일이 기록 중인 위치로 확장되며 이전 EOF와 쓰기 시작점 사이의 갭은 0으로 채워져야 한다. EOF 이후의 위치에서 시작하는 읽기는 바이트를 반환하지 않는다.
- EOF를 훨씬 넘어 쓰는 것은 많은 블록들이 완전히 0이 될 수 있다. 몇몇의 파일 시스템들은 암묵적으로 제로화된 블록을 위해 실제 데이터 블록을 할당하고 쓴다(wrtie). 다른 파일 시스템들은 블록이 명시적으로 작성될 때까지 이런 블록을 할당하지 않는다. 후자 파일 시스템은 "sparse file"을 지원한다. 파일 시스템에서 할당 전략 중 하나를 채택할 수 있다.
여기까지 pintos project4의 Indexed and extensible files와 관련된 깃북 내용 정리다. 그럼 테스트를 돌려보
기 전에 먼저 makefile의 일부를 고쳐야 한다.
filesys/Make.vars 파일을 보자.
# -*- makefile -*-
os.dsk: DEFINES = -DUSERPROG -DFILESYS -DEFILESYS
KERNEL_SUBDIRS = threads devices lib lib/kernel userprog filesys
KERNEL_SUBDIRS += tests/threads tests/threads/mlfqs
TEST_SUBDIRS = tests/threads tests/userprog tests/filesys/base tests/filesys/extended tests/filesys/mount
GRADING_FILE = $(SRCDIR)/tests/filesys/Grading.no-vm
# Uncomment the lines below to enable VM.
# os.dsk: DEFINES += -DVM
# KERNEL_SUBDIRS += vm
# TEST_SUBDIRS += tests/vm tests/filesys/buffer-cache
# GRADING_FILE = $(SRCDIR)/tests/filesys/Grading.with-vm
아래 문단을 보면 VM 활성화를 위해 주석처리를 해제하라고 되어 있다.
# -*- makefile -*-
os.dsk: DEFINES = -DUSERPROG -DFILESYS -DEFILESYS
KERNEL_SUBDIRS = threads devices lib lib/kernel userprog filesys
KERNEL_SUBDIRS += tests/threads tests/threads/mlfqs
TEST_SUBDIRS = tests/threads tests/userprog tests/filesys/base tests/filesys/extended tests/filesys/mount
GRADING_FILE = $(SRCDIR)/tests/filesys/Grading.no-vm
# Uncomment the lines below to enable VM.
os.dsk: DEFINES += -DVM
KERNEL_SUBDIRS += vm
TEST_SUBDIRS += tests/vm tests/filesys/buffer-cache
GRADING_FILE = $(SRCDIR)/tests/filesys/Grading.with-vm
만약 여기에 #을 제거하지 않는다면 테스트는 고사하고 VM 부분에서 말도 안 되는 에러문구가 뜨는 것을 보게 될 것이다. 그럼 다시 테스트 돌려보기!

여기까지 하고 테스트들 돌려보면 176개의 fail이 나온다.

패스는 프로젝트 1 해당 부분만 통과되고. 다음 파트도 계속 해봐야겠다.
'개발자 도전기 > [OS] pintOS' 카테고리의 다른 글
| pintOS | Project 4 회고 (0) | 2021.11.02 |
|---|---|
| pintOS | Project 4 | Subdirectories and Soft Links (0) | 2021.10.30 |
| pintOS | Project 4 | Introduction (0) | 2021.10.28 |
| pintOS | Project 3 회고 (0) | 2021.10.28 |
| pintOS | Project 3 | 버그잡자 (1) | 2021.10.22 |


댓글